(Yep, that was straight from Wikipedia)
Examples of scraping from tables/structured data
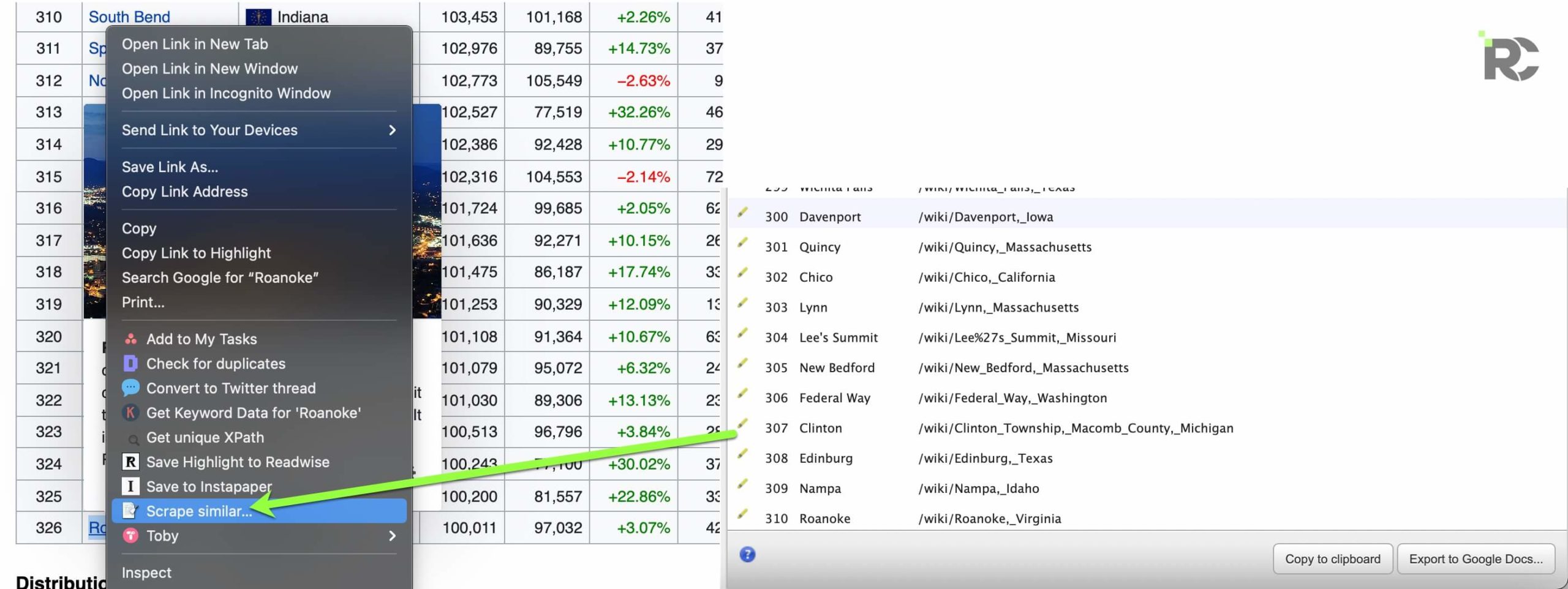
Using the “Scraper” Chrome Extension makes it really easy to extract similar types of content.
[Note: I could tell this was a tabular format, which is what we’re going for in identifying a consistent and scrap-able format.]

I would reiterate that page consistency is pretty key here. Even when something might not look like it has a table structure, it still can be scrap-able.

Tip using the “Scraper” Chrome Extension for tables
You’ll often have the best luck going to the end of a long table and “starting” there, vs at the start of the table.
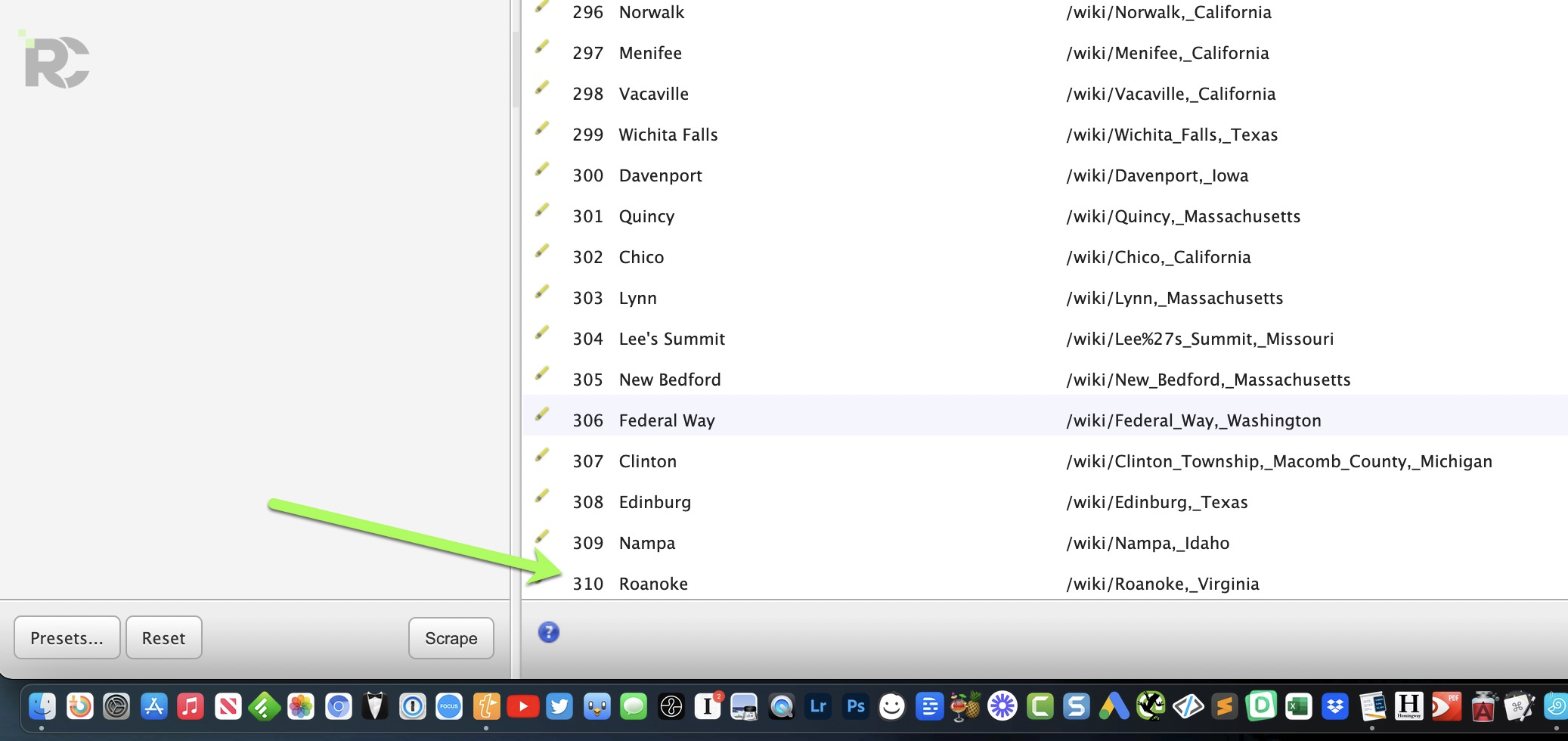
Example is a Wikipedia table of the largest cities in the US:

Which will then give you all the results in the table immediately after:
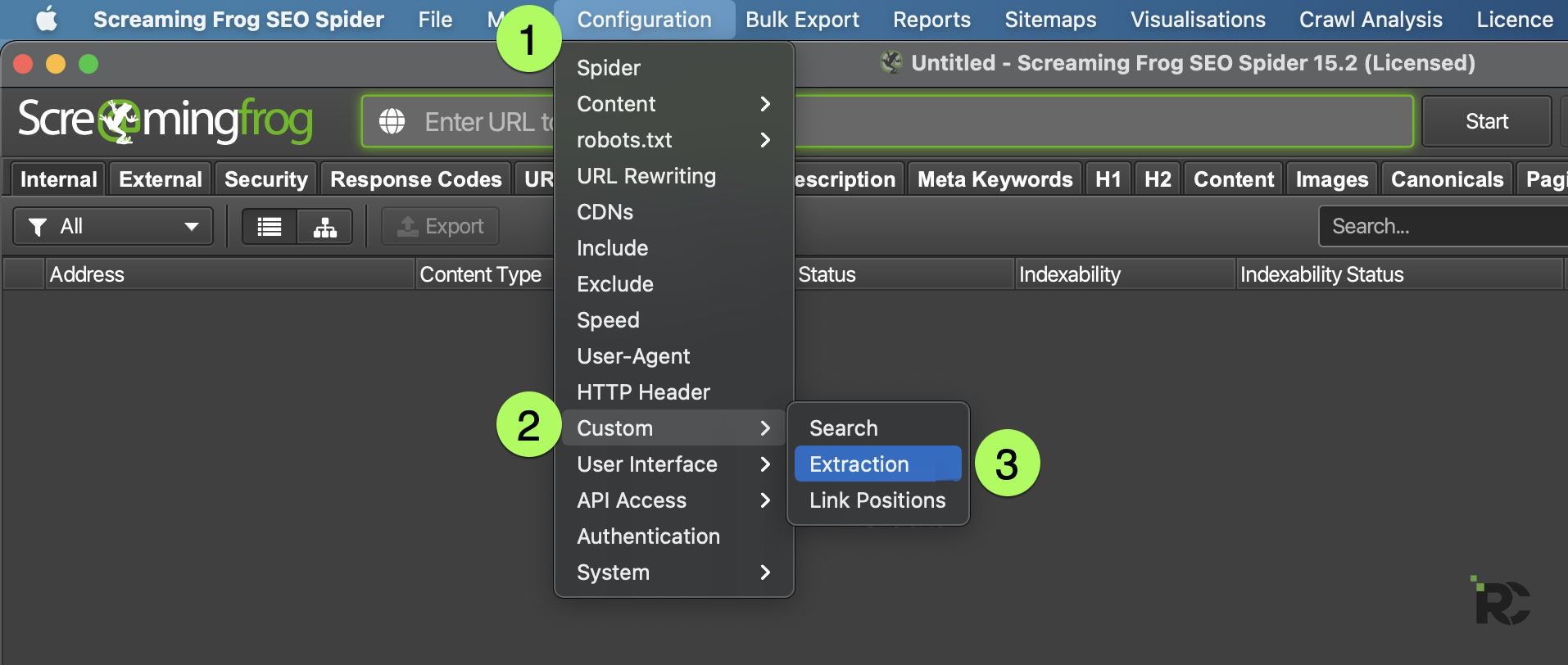
Screaming Frog (my crawler of choice) also has the option to “scrape” pages or entire websites. This is the more comprehensive and customizable solution. I do think it makes sense for certain types of Marketers to get a copy of Screaming Frog, as it can only help you become more technical and quite possible how much you don’t like to do a task – then how to better hire for it 🙂
Here is how you set up Screaming Frog to extract:
Then you would choose how you want to extract the text from the crawl scope:
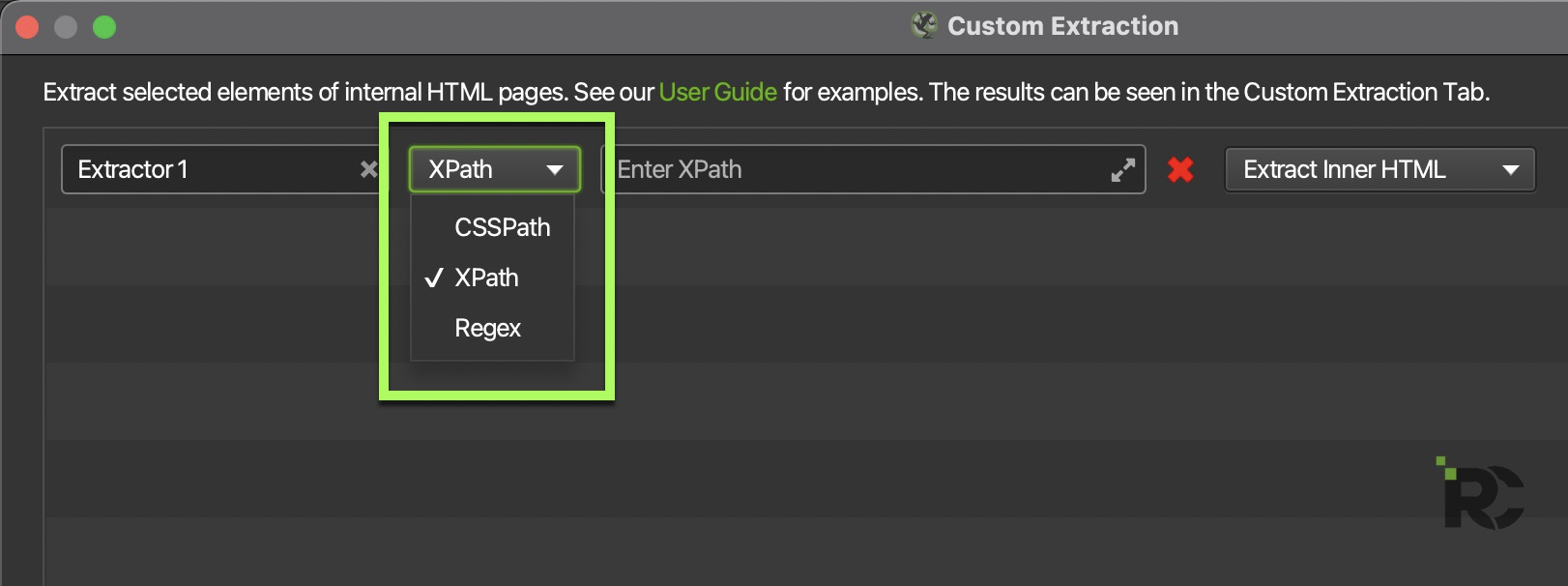
XPATH is my preferred language to try and scrape with first. Stands for XML Path Language and I’ve found is the easiest to understand, set up, and way to get data back in the cleanest format.
P.S. Screaming Frog has a wealth of knowledge on their site: https://www.screamingfrog.co.uk/seo-spider/user-guide/
What to look for to know if you can scrape
One word: Structure.
You’ll get better at looking for this over time, but tables are really your best friend here. I usually start by looking for tables on Wikipedia – as not all tables are created equal.
If it looks consistent to your eye/on the page – it usually will work with.
However, this is exactly what the “Scraper” chrome extension is for. Test quickly and get a sample of what your data could look like if you crawled the entire page or site with Screaming Frog.
(Note: I say this because Crawlers can be a resource hog on your computer. Granted, I have a 64gb RAM computer with several cores – but most don’t have that much to bargain with and you’ll need to be more conservative and careful when scraping. The default settings I’ve found to work quite well. I would just crawl individual pages unless you really need to crawl the entire site.)
Tools to Scrape with
- Scraper for Chrome (Preferred)
- Screaming Frog (A lot more powerful)
- OutWit Hub (Similar to Screaming Frog, great for scraping search results)
- PhantomBuster (more for social platforms, but quite powerful)
- ScrapeBox Pro (Old one but still some benefits to this)
- Python (Computer Programming Language – knowing this language is primarily used helps you better learn enough to hire for it)
I hope this helped you get a better idea of the wonderful world of Scraping!
Note: Please scrape responsibly. 🐸 😳 🤓